올거나이즈, ‘올인원 벤치마크’로 AI 모델 성능 진단
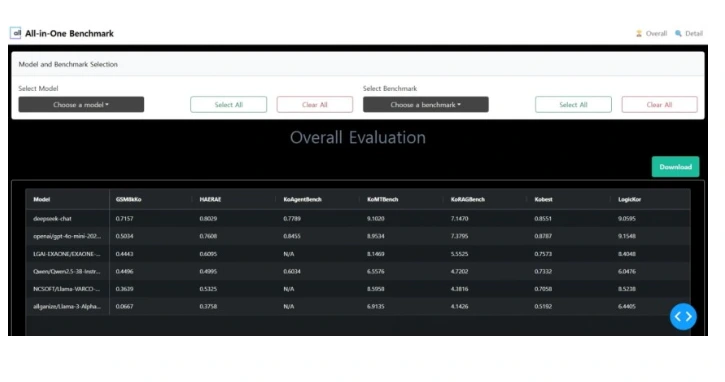
올거나이즈 가 인공지능 거대언어모델(LLM)의 에이전트 성능을 평가하는 ‘올인원 벤치마크’를 공개했다.
기업이 적합한 AI 모델을 선택할 수 있도록 돕기 위해 마련된 이 플랫폼은 툴 활용 능력, 맥락 이해, 문제 해결 능력 등을 종합적으로 평가한다.
올인원 벤치마크는 다양한 산업 분야에서의 활용 가능성을 테스트하며, 12개 LLM의 성능 데이터를 제공한다.
주요 평가 지표로는 툴 콜링 능력을 평가하는 ‘BFCL’과 ‘FunctionChatBench’, 실제 산업 문제 해결 능력을 측정하는 ‘TauBench’가 있다.
플랫폼을 통해 새로운 LLM도 자동으로 평가가 가능하며 기존 대비 평가 시간이 약 20분으로 대폭 단축된다.
또한, 공개된 데이터셋 ‘ArenaHard’, ‘Kobest’, ‘HAERAE’ 등 12개 벤치마크를 통해 에이전트 외에도 언어 이해력, 명령 준수 능력 등 다양한 지표를 평가한다.
올거나이즈는 오픈소스로 공개된 딥시크 V3 에이전트를 테스트해 ‘GPT-4o 미니’와 유사한 성능을 확인했다고 밝혔다.
이창수 올거나이즈 대표는 “기업이 생산성 향상을 위해 AI 모델을 도입하는 데 도움이 되는 LLM 평가 플랫폼을 지속적으로 업데이트해 나갈 예정”이라고 언급했다.
이어 “나아가 에이전트 역할을 제대로 수행하는 LLM을 개발하기 위해 기존 LLM의 에이전트 성능을 확인하고 이를 향상시키기 위한 학습 방법을 심도 있게 연구하고 있다”고 말했다.
배동현 (grace8366@sabanamedia.com) 기사제보
관련 기사

중소 협력사 위한 LGU+ 상생 행보…300억 대금 조기 지급

경찰청 딥시크 이용 제한 조치…전국 경찰 PC 보안 강화

효성ITX, H3C와 총판 계약…네트워크 시장 확대

방심위, 인터넷 사기·딥페이크 범죄 예방 영상 공개

로커스체인 테스트넷 개방…개발자 생태계 확대

에브리봇, 침구 로봇청소기 X1 완판…공급 확대 계획