SK텔레콤 이 자체 개발한 한국어 거대언어모델(LLM) ‘에이닷 엑스 3.1’을 글로벌 오픈소스 커뮤니티 허깅페이스(Hugging Face)에 공개하며 AI 기술 대중화에 박차를 가하고 있다.
SK텔레콤 은 24일 340억개(34B)와 70억개(7B) 규모의 두 가지 버전으로 구성된 에이닷 엑스 3.1 모델을 오픈소스로 등록했다고 밝혔다.
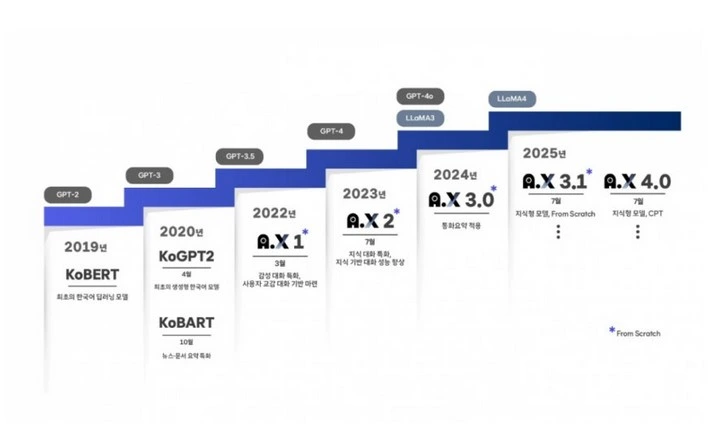
에이닷 엑스 3.1은 SK텔레콤이 프롬 스크래치(from scratch) 방식으로 설계부터 학습까지 독자적으로 개발한 LLM으로, 기존 모델인 3.0보다 한국어 외에도 수학과 코딩 능력을 대폭 향상시킨 것이 특징이다.
특히 3.1은 추론 기반의 응용 성능을 강화해 실사용에 적합한 경량형 AI 모델로 개발됐다.
SKT는 현재 프롬 스크래치 방식과 CPT(Continuing Pre-training) 방식이라는 두 가지 트랙으로 AI 모델을 병행 개발하고 있다.
CPT는 해외 공개 모델을 기반으로 한국어 데이터를 추가 학습시키는 방식이며, 대표적으로 720억개 파라미터 규모의 ‘에이닷 엑스 4.0’이 있다.
이 모델은 현재 AI 통화 요약 등 실제 서비스에 적용돼 실시간 응답 성능을 향상시키고 있다.
에이닷 엑스 3.1은 상대적으로 작은 규모에도 불구하고 에이닷 엑스 4.0 대비 약 90% 수준의 성능을 보여준다.
한국어 능력 평가 벤치마크인 KMMLU에서 3.1은 69.20점을 기록해 4.0(78.3점)의 88% 수준에 도달했다.
한국 문화 이해도 평가인 CLIcK에서도 3.1은 77.1점, 4.0은 85.7점을 기록해 기술적 우수성을 입증했다.
SK텔레콤은 이미 2019년 국내 최초의 한국어 딥러닝 언어 모델 ‘KoBERT’를 시작으로, GPT-2 기반 ‘KoGPT2’, 문서 요약에 특화된 ‘KoBART’ 등을 오픈소스로 공개하며 한국어 AI 기술 저변 확대에 기여해 왔다.
이러한 기술력은 과학기술정보통신부가 주관하는 ‘독자 AI 파운데이션 모델 개발 사업’ 참여로도 이어지고 있다.
SKT는 크래프톤, 포티투닷, 리벨리온, 셀렉트스타, 라이너, 서울대·KAIST 연구진 등과 컨소시엄을 구성해 ‘소버린 AI’ 기술 개발을 공동 추진 중이다.
이들은 텍스트뿐 아니라 이미지, 음성, 영상 등 다양한 데이터를 통합 처리하는 옴니모달(Omni-modal) AI 모델 개발에 집중하고 있다.
김태윤 SKT 파운데이션 모델 담당은 “각 분야 선도기업들과의 컨소시엄 구성으로 향후 소버린AI분야에서 새로운 성과를 만들어낼 것"이라며, "국내AI생태계를 종합적으로 고려해 혁신적인 인공지능 모델을 선보일 계획”이라고 말했다.
배동현 ([email protected]) 기사제보













댓글을 남기려면 로그인 해주세요.